
Video Compression
Introduction
우리가 보는 모든 동영상은 압축되어 있습니다. 압축하지 않은 동영상은 크기가 너무 커서 스트리밍 또는 저장하기 어렵기 때문입니다.
예를 들어, FHD 해상도의 영상이 압축되어 있지 않다면, 1초짜리 영상은 1920 * 1080 * 3 / 2 * 60 = 187MB의 크기를 가집니다 (4:2:0, 60fps). 1분이면 11.2GB, 1시간이면 671.8GB의 크기입니다. 이러한 크기의 동영상을 스트리밍 하거나 저장하는 것은 현실적으로 어렵습니다.
따라서 비디오를 서비스할 때 코덱을 통해 비디오를 압축하는 것은 필수적입니다. 이번 글에서는 동영상의 데이터를 줄이고 압축하는 원리에 대해 설명합니다.
Codec이란?
encoder + decoder를 합친 말입니다. 영상을 압축 및 압축 해제 할 수 있는 인코더와 디코더를 합쳐서 부르는 말입니다.
Chroma Subsampling
비디오 데이터를 줄이는 방법 첫 번째는, 색상에 대한 정보를 일부 버리는 것입니다.
인간의 눈은 밝기에 민감하고 색상에는 상대적으로 둔감하다는 특징이 있습니다. 색상에 민감한 원추세포가 빛에 민감한 간상세포보다 훨씬 적기 때문이죠. (이러한 인간의 시각의 특성을 Human Visual System (HVS)라고 합니다.)
이러한 특징을 이용해, 상대적으로 둔감한 색상 정보를 일부 버림으로써 데이터를 아낄 수 있습니다. 물론, 데이터를 버렸기 때문에 화질이 나빠지는 것은 피할 수 없어요. 그래도 대부분의 경우 데이터를 아끼기 위해 색상 정보들을 날려버린답니다. 그럼 색상 정보들을 어떻게 줄일까요?
Color Format
먼저 색상을 표현하는 방식에 대해 얘기하겠습니다. 이미지에서 각 픽셀의 정보를 표현하는 방식은 여러 가지가 있어요.
직관적인 방법으로는 각 픽셀을 빛의 3원 색인 Red, Green, Blue 정보로 표현하는 겁니다. R, G, B를 적절히 섞으면 모든 색상을 표현할 수 있으니까요.
또 다른 방법으로는, 픽셀을 밝기와 색차 정보로 표현할 수도 있습니다. Y (밝기), Cb(파란색의 색차), Cr(빨간색의 색차), Cg(초록색의 색차)로 표현하는 것이죠. 그런데, 꼭 세 가지의 색차 정보를 기록할 필요는 없습니다. 서로 다른 두 개의 색차 정보를 알면 나머지 하나도 정해진 공식에 따라 구할 수 있기 때문이죠. 그래서 보통 Y, Cb, Cr 세 개에 대한 정보를 기록합니다.


왼쪽이 RGB, 오른쪽이 YCbCr 방식으로 사진을 분리한 것이에요. 아래 세 가지 정보를 더하면 맨 위의 결과물이 나옵니다. 같은 이미지를 서로 다른 방식으로 표현한 것뿐이에요.
Chroma Subsampling

(위의 그림에서 Cb = U, Cr = V로 생각해 주세요.)
색상 정보를 날리지 않은 형태가 4:4:4입니다. Y 8픽셀, Cb 8픽셀, Cr 8픽셀이 모여 8픽셀의 그림을 만드는 것을 볼 수 있어요. (그림에는 U+V가 하나처럼 표현되어 있지만, 각각 8픽셀씩 있다고 생각해 주세요.)
반면에 4:2:0 방식에서는 Y 8픽셀, Cb 2픽셀, Cr 2픽셀이 모여 8픽셀의 이미지가 되는 것을 볼 수 있죠. 물론 4:4:4 방식이 4:2:0에 비해 더 선명합니다.

자세히 보시면 4:2:0보다 4:4:4의 화질이 더 좋다는 것을 알 수 있습니다. 그럼에도 불구하고, 많은 데이터를 줄일 수 있기 때문에 보통 4:2:0와 같이 chroma subsampling된 방식으로 영상을 표현합니다.
Data compression
본격적으로 영상 압축을 배우기 전에, 일반적인 데이터들을 압축하는 방법을 살펴보겠습니다.
수많은 데이터 중 꼭 동영상만 압축을 하는 것은 아닙니다. 문서, 음악, 이미지 등 다양한 종류의 파일들을 압축할 수 있습니다. 이미 우리가 알집 등의 프로그램을 사용해서 파일들을 압축한 경험이 있을 겁니다. 그 중 대표적인 방법 몇 개만 소개해 보겠습니다. 물론 이러한 압축 방식 역시 동영상 압축에서 사용됩니다.
Variable-length code
심볼(문자)에 서로 다른 크기의 비트를 할당하여 데이터를 줄이는 방식입니다.
예를 들어, this is an example of a huffman tree를 압축해 볼까요? 앞의 문장에서는 space, a, e, f, h, i, l, m, n, o, p, r, s, t, u, x, 총 16가지의 문자가 등장합니다. 16개의 문자를 표현하기 위해서는 4비트가 필요하고, 때문에 고정 비트를 사용할 경우 36개의 문자 x 4bit = 144bit가 필요합니다.
하지만 허프만 코딩을 통해, 자주 사용되는 문자에는 짧은 길이의 비트를 할당하고, 자주 사용되지 않는 문자에는 긴 길이의 비트를 할당할 수 있습니다. 아래처럼요.
| 문자 | 발생 빈도 | 코드 |
|---|---|---|
| space | 7 | 111 |
| a | 4 | 010 |
| e | 4 | 000 |
| f | 3 | 1101 |
| h | 2 | 1010 |
| i | 2 | 1000 |
| m | 2 | 0111 |
| n | 2 | 0010 |
| s | 2 | 1011 |
| t | 2 | 0110 |
| l | 1 | 11001 |
| o | 1 | 00110 |
| p | 1 | 10011 |
| r | 1 | 11000 |
| u | 1 | 00111 |
| x | 1 | 10010 |
위의 코드를 사용해서 this is an example of a huffman tree를 표현할 경우 134bit을 사용해서 표현할 수 있습니다. 무려 10bit가 줄었군요!😆 훨씬 더 긴 문자열에서는 더 큰 압축률을 보여줄 수도 있습니다.
Run-level Encoding
Run-length encoding과 유사합니다. 0인 숫자가 많을 때 압축률이 좋습니다.
16, 0, 0, -3, 5, 6, 0, 0, 0, 0, -7,..이라는 숫자열을
(0,16), (2, -3), (0,5), (0,6), (4,-7)으로 바꾸는 방식입니다.
괄호 안의 숫자는 자신의 숫자 앞에 0이 몇 개가 있냐를 나타냅니다. 여기서 중요한 점은 0이 많으면 압축률이 좋다! 입니다. 나중에 설명드리겠지만 이 원리를 사용해서 동영상 인코더는 최대한 많은 0을 만들기 위해 많은 노력을 합니다.
Arithmetic coding
Summary
영상 압축뿐만 아니라 다양한 분야에서 사용되는 데이터 압축 방법에 대해 알아봤습니다. 아래의 내용은 꼭 기억해 주세요!
“0이 많을수록 압축이 잘 된다!”
Video Compression
그렇다면 이제 이미지를 최대한 0인 값으로 바꿔줘야 합니다. 중복되는 데이터를 제거함으로써, 데이터들을 0으로 바꿀 수 있습니다. 구체적인 예를 들어 설명드리겠습니다.
Inter prediction
영상은 여러 프레임의 연속적인 집합입니다. 프레임과 인접한 프레임의 데이터는 매우 비슷합니다. 그렇다면 굳이 매 프레임마다 모든 데이터를 보내야 할 필요가 있을까요? 그럴 필요 없이 이전 프레임과 현재 프레임을 뺀 데이터를 보낸다면, 많은 중복되는 데이터들이 사라질 테고, 이를 통해 많은 데이터를 아낄 수 있습니다.



위와 같이 첫 번째 프레임과 두 번째 프레임은 매우 유사합니다. 그렇다면 두 번째 프레임에 대한 정보를 그대로 보낼 필요가 있을까요? 두 번째 프레임에서 첫 번째 프레임을 뺀 나머지만 보낸다면 위와 같이 대부분의 데이터가 0으로 바뀔 거에요. 여기서 프레임에서 이전 프레임을 뺀 결과물을 residual이라고 합니다. 대부분이 0인 residual을 아까 배웠던 run-level coding으로 압축해서 보낸다면 데이터를 효과적으로 압축해서 보낼 수 있습니다.
Motion estimation and compensation
위처럼 단순하게 프레임과 프레임을 뺀 residual을 보내는 것만으로도 데이터를 압축할 수 있습니다. 그러나 요즘의 코덱들은 저것보다 더 높은 압축률을 달성하기 위해 더 진보된 방식을 사용합니다. 바로 block-based coding이에요. 아까는 그냥 프레임과 프레임을 빼서 보냈죠? 그러나 block-based coding에서는 아래와 같은 과정을 거칩니다.
- 프레임을 더 작은 크기의 균일한 격자들로 나눕니다. 이렇게 나눠진 각 블록 단위로 압축을 진행합니다.
- 이전 프레임에서 현재 블록과 가장 비슷한 위치를 찾습니다.
- 가장 비슷한 위치와 현재 블록 위치의 차이를 motion vector라고 합니다.
- 현재 블록과 가장 비슷한 위치의 블록을 뺍니다.
- 빼고 난 데이터를 residual이라고 합니다.
- 데이터를 압축할 때는 residual을 run-level 방식으로 압축한 뒤 motion vector와 함께 저장합니다. 최대한 비슷한 위치를 찾아서 빼주면 residual이 대부분 0이 될거고, 그러면 압축율이 높아지겠죠?
이러한 block-based 방식으로 residual을 구한게 아래 그림입니다.

위에서 프레임과 프레임을 뺀 residual보다 훨씬 0에 가까워졌죠? 이러한 방식으로 temporal redundancy를 제거하여 많은 데이터를 아낄 수 있습니다.
Intra prediction
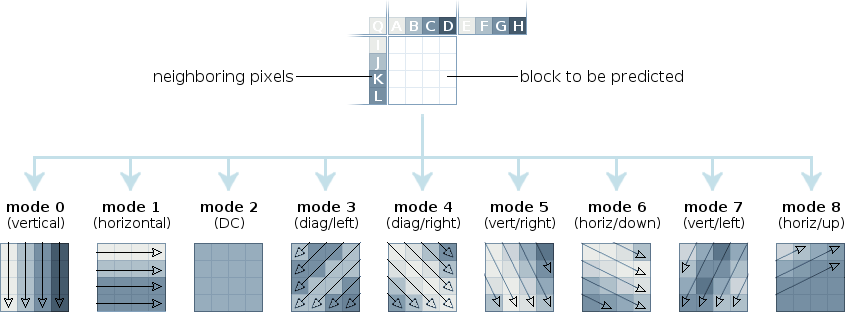
프레임 안에서도 많은 중복이 있습니다. 예를 들어 푸른 하늘을 떠올려볼까요? 대부분이 하늘색입니다. 반복해서 똑같은 하늘색 데이터를 보낼 필요가 없습니다. 이러한 frame 안에서의 공간적인 중복을 제거하기 위해 사용하는 것이 intra prediction입니다.

위의 그림에서 하늘에 해당하는 블록을 압축할 때, 블록의 모든 픽셀을 저장하지 않고 아래와 같이 두 가지 정보만 저장합니다.
- 모드 정보
- prediction 방식을 나타냅니다. DC 모드의 경우, 블록 주변 픽셀의 평균을 현재 블록에 채워 넣습니다.
- Residual
- 원본 이미지와 모드 정보를 토대로 prediction된 (채워 넣어진) 이미지를 뺀 결과물입니다.
prediction이 잘 됐다면, residual 데이터들은 많은 0을 가질 테고, 결과적으로 높은 압축률을 보일 수 있습니다. 이러한 방식으로 spatial redundancy를 제거해 많은 데이터를 아낄 수 있습니다.
Transform and Quantization
inter, intra prediction을 통해 residual을 만들었는데, 이것만으로는 좀 아쉽습니다. 더 데이터를 줄일 방법이 없을까 고민해 봅니다. 이때 또다시 HVS (Human Visual System)을 생각해 보니.. 인간의 눈은 이미지의 low-frequency에 민감하고 high-frequency에 둔감합니다. 따라서 이미지에서 high-frequency 성분들을 날려버리기로 합니다!
그런데.. 이미지에서 high frequency 영역을 어떻게 날릴까요? 아래와 같은 순서로 날립니다.
- 블록을 주파수 도메인으로 변환합니다. Fourier transform을 이용하면 이미지를 주파수 도메인으로 변환할 수 있습니다.
- 변환된 블록을 quantization 합니다.
quantization 과정에서 저주파수 성분도 일부 날아가겠지만, 일반적으로 저주파수 성분이 훨씬 크기 때문에 고주파수 성분이 상대적으로 더 큰 영향을 받습니다. 최종 결과는 아래와 같겠죠? 왼쪽이 원본, 오른쪽이 quantization 후 이미지 입니다.


물론 여기서 고주파수 성분들을 날려버렸기 때문에, 더 이상 압축된 영상은 압축되기 전과 똑같지 않습니다. 영상 압축 시 화질이 열화되는 현상은 바로 여기에서 일어납니다. DC 성분이 날아가면서 blocking artifact가 생기고, high-frequency 성분이 날아가면서 ringing artifact가 생기기도 하죠. 하지만 quantization을 하면 압축률이 상당히 많이 올라가기 때문에, 화질이 안 좋아지는 것을 감안하더라고 대부분 quantization을 합니다. quantization을 하지 않으면 손실이 없는 loseless 압축이 됩니다.
Statistical Redundancy
Predictive coding
확률적인 중복들을 제거할 수도 있습니다. 그중 한 가지 예만 설명드리겠습니다.

위의 그림에서 우리가 압출할 블록 E의 motion vector는 주변 블록 A, B, C의 motion vector와 유사할 가능성이 매우 높습니다. 매 블록마다 모션 벡터를 그대로 보내지 않고, 주변 블록들의 모션 벡터와의 차이만 보낸다면, 더 작은 데이터가 필요하므로 데이터를 아낄 수 있습니다. 이렇게 통계적인 중복을 줄이는 방식들이 코덱 곳곳에 녹아있습니다.
Entropy coding
또한 위에서 배웠던 variable-length coding, run-level coding, arithmetic coding 등의 방식을 적용하여 데이터를 압축합니다.
Summary

위의 그림은 AV1 코덱의 압축 과정을 나타낸 그림입니다. 아래와 같이 요약할 수 있겠네요.
- Inter prediction : temporal redundancy 제거
- Intra prediction : spatial redundancy를 제거
- Transform and Quantization : high-frequency 제거
- Entropy coding : statistical redundancy 제거
Loop filtering은 다루지 않았었는데요, blocking artifact나 ringing artifact 등, transform and quantization의 부작용을 줄이기 위해 필터링하는 과정입니다.
생략된 부분이 많기도 하고, 글로 표현하다 보니 충분하지 않은 설명들도 있습니다. 그래도 코덱이 궁금하신 분들에게 도움이 되었으면 좋겠습니다. 😆
참고하면 좋은 자료들
- Iain E. Richardson, The H.264 Advanced Video Compression Standard
- Vivienne Sze, Madhukar Budagavi, Gary J. Sullivan, High Efficiency Video Coding (HEVC)
- 카도노 신야, H.264 AVC 비디오 압축 표준
- 심동규, 조현호, 고효율 영상 부호화 기술 HEVC 표준 기술의 이해
Leave a comment